| Autor |
Nachricht |
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
 Asterix Verfasst am: 25. Jul 2012 12:59 Titel: Korrelationsterm in Fehlerfortpflanzung Asterix Verfasst am: 25. Jul 2012 12:59 Titel: Korrelationsterm in Fehlerfortpflanzung |
 |
|
Möchte bei der Fehlerschätzung einer linearen Regression f(x): y=a+bx den hier http://de.wikipedia.org/wiki/Fehlerfortpflanzung beschriebenen Korrelationsterm berechnen. Die patiellen Differentiale sind klar

 . .
Wie wird aber u(a,b) berechnet? |
|
 |
Jannick
Gast
|
| Jannick Verfasst am: 25. Jul 2012 13:20 Titel: |
|
|
Das ist nicht so trivial. Normalerweise wird die sog Korrelations oder Kovarianzmatrix (siehe wiki: Korrelationsmatrix) allerdings vom Fitprogramm ausgegeben. Die entsprechenden Kovarianzen sind darin enthalten. Die Wurzel der Diagonalelemente ist hierbei der Fehler der Fitparameter, da &=&Var(X)) . Die entsprechende Matrix ist dann natuerlich symmetrisch und in deinem Fall ist die gesuchte Kovarianz einfach Element 12 oder 21 . Die entsprechende Matrix ist dann natuerlich symmetrisch und in deinem Fall ist die gesuchte Kovarianz einfach Element 12 oder 21 |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 25. Jul 2012 14:08 Titel: |
|
|
| Jannick hat Folgendes geschrieben: | | Das ist nicht so trivial. |
Jetzt verstehe ich mindestens einmal weshlb im Internet kein "How To" für die vollständige Fehlerfortpflanzung bei der linearen Regression zu finden ist.
Kann Excel die betreffenden Werte liefern und wenn ja, wie ? Mit den vorhandenen Funktionen oder einem der Analyse-Tools ? In der Excel-Hilfe liefern die Suchbegriffe "Korrelationsmatrix" und "Kovarianzmatrix" keine Treffer.
Nachträglich noch folgende Frage:
Die Fehler werden ja nicht bezogen auf x und y berechnt sondern bezogen auf a und b. Bedeutet dies nicht, dass dann die Korrelationsmatrix zwischen a und b zu berechnen wäre? |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 25. Jul 2012 17:56 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | [...]
Kann Excel die betreffenden Werte liefern und wenn ja, wie ? Mit den vorhandenen Funktionen oder einem der Analyse-Tools ? In der Excel-Hilfe liefern die Suchbegriffe "Korrelationsmatrix" und "Kovarianzmatrix" keine Treffer.
Nachträglich noch folgende Frage:
Die Fehler werden ja nicht bezogen auf x und y berechnt sondern bezogen auf a und b. Bedeutet dies nicht, dass dann die Korrelationsmatrix zwischen a und b zu berechnen wäre? |
Ich schaue einmal kurz ins Skript:
Für die lineare Regression bestimmst du die chi² Funktion
]^{2}}{\sigma_{i}^{2}})
und minimierst diese 
Dadurch wird aus der Varianz eine Matrix mit Vier Einträgen.
In der ersten Spalte steht 
und in der zweiten: 
Die Korrelation macht sich jetzt in den Diagonalelementen Bemerkbar. Allgemein gilt:
^{-1}) . .
Als Maß für die Korrelation kann man den Korrelationskoeffizienten angeben, dieser lautet für zwei Messwerte zi,zj in seiner allgemeinen Form:
(zj-zj*)] }{ \sigma_{i} \sigma_{j}} ) |
|
|
Jannick
Gast
|
| Jannick Verfasst am: 25. Jul 2012 19:35 Titel: |
|
|
|
Mit Excel kenne ich micht nicht so aus. Einigermassen empfehlenswert ist das kostenlose Programm QTIPlot, welches linear und nichtlinear Fitten kann und in beiden Faellen auch die Korrelationsmatrix ausgibt. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 26. Jul 2012 09:59 Titel: |
|
|
| Jannick hat Folgendes geschrieben: | | Einigermassen empfehlenswert ist das kostenlose Programm QTIPlot, welches linear und nichtlinear Fitten kann und in beiden Faellen auch die Korrelationsmatrix ausgibt. |
Habe es heruntergeladen und ein Beispiel eingegeben. Die angezeigten Werte sind:
| Code: | Lineare Regression von Datensatz: Tabelle1_2, unter Verwendung der Funktion: A*x+B
Gewichtungsmethode: Keine Gewichtung (alle w_i = 1)
Von x = -1.804571429000000e+01 bis x = 1.985428571000000e+01
B (y-intercept) = 2.728830057428340e-09 +/- 2.260177763664549e+00
A (slope) = 5.056562001484564e-01 +/- 1.492427732868604e-01
--------------------------------------------------------------------------------------
Chi^2/doF = 3.575882466354579e+01
R^2 = 0.696593261905147
Angepasstes R^2 = 0.54488989285772
RMSE (Standardabweichung) = 5.97986828145452
RSS (Summe der quadrierten Restwerte) = 178.794123317729 |
Welche Werte entsprechen den  ? ?
Wenn die Korrelation berechnet wird werden diese für jeden Wert bezogen auf das mittlere n in einer Liste ausgegeben, also auch nicht als Matrix. |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 26. Jul 2012 10:07 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | | [...]Welche Werte entsprechen den ?[...] |
keiner. Ausgegeben ist nur  und und  . . |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 26. Jul 2012 10:33 Titel: |
|
|
Wie komme ich denn and das ? Muss dafür die lineare Regression vielleicht für beide Fälle berechnet werden:
 und und
 ? ?
Konkret, wie berechne ich mit einem vorhandenen Datensatz x, y den Wert ? |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 26. Jul 2012 10:46 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | Wie komme ich denn and das ? Muss dafür die lineare Regression vielleicht für beide Fälle berechnet werden:
und
?
Konkret, wie berechne ich mit einem vorhandenen Datensatz x, y den Wert ? |
s.o. i=A, j=B. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 26. Jul 2012 11:57 Titel: |
|
|
Wenn ich mir das  im Nenner anschaue, dann wird es happig. Hat das früher schon jemand berechnet bzw. gibt es einen Link, der das Resultat zeigt? im Nenner anschaue, dann wird es happig. Hat das früher schon jemand berechnet bzw. gibt es einen Link, der das Resultat zeigt? |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 26. Jul 2012 21:36 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | | Wenn ich mir das im Nenner anschaue, dann wird es happig. Hat das früher schon jemand berechnet bzw. gibt es einen Link, der das Resultat zeigt? |
Natürlich hat das schon jemand mal berechnet, jedes vernünftige Fitprogram arbeitet nach diesem Verfahren.
Es sind außerdem nicht "das sigmai²", sondern DIE "sigmai²", da jeder Messwert yi unter Umständen eine andere Messunsicherheit hat (ist xi auch Fehlerbehaftet, geht es prinzipiell genauso, wird aber leicht komplizierter). (Ist die Messunsicherheit für alle yi gleich, so ist sigmai konstant und du kannst es somit vor die Summe ziehen.)
Wenn du die Ableitungen bildest, leitest du nach a und b ab! (nur, um Misssverständnis zu vermeiden) |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 26. Jul 2012 23:55 Titel: |
|
|
| Chillosaurus hat Folgendes geschrieben: | | Es sind außerdem nicht "das sigmai²", sondern DIE "sigmai²", ... |
Das war insofern klar als dieses sigma noch ein i hat und sich deshalb auf jedes Residual bezieht. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 10:25 Titel: |
|
|
| Chillosaurus hat Folgendes geschrieben: | | Natürlich hat das schon jemand mal berechnet, jedes vernünftige Fitprogram arbeitet nach diesem Verfahren. |
Anscheinend sind dann viele Fitprogramme nicht "vernünftig" da sie die Kovarianz unberücksichtigt lassen oder, sofern berechnet, dessen Wert nicht separat liefern. So habe ich bspw. beim eingangs empfohlenen QTIPlot diesen Term nicht finden können. Oder habe ich ihn übersehen? Welche anderen Fitprogramme (für Windows 7) sind denn in dieser Hinsicht "vernünftig"? |
|
|
Jannick
Anmeldungsdatum: 25.07.2012
Beiträge: 107
|
| Jannick Verfasst am: 27. Jul 2012 11:38 Titel: |
|
|
Eine Kurzanleitung fuer QTIPlot:
- Du musst 3 Spalten anlegen, naemlich X Y und Yerr. Dabei kannst du mit rechtsklick auf eine Spalte sie als Yerr setzen.
- Nun gehst du auf Analyse und dort auf Fitwizard.
- Gib die Lineare Funktion als Formel ein und bei Parameter die entsprechend anzupassenden Werte. Also:
Parameter: a,b
Funktion: a*x+b
- Anpassen ->Dort waehlst du instrumentelle Gewichtung. Das bedeutet, dass er genau mit der Formel, die Chillosaurus gepostet hat arbeitet.
- Nun nochmal auf anpassen Klicken worauf er fittet.
- Benutzerdefinierte Ausgabe: Kovarianzmatrix ausgeben
Voila |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 12:59 Titel: |
|
|
Danke, Jannick, für die Kurzanleitung.
Nach fast 40 Jahren seit der Uni scheinen meine Gehirnwindungen nicht mehr ganz so fit zu sein. Bemerke nämlich ert jetzt, dass die sigma i im Nenner bzw. die Yerr nichts anderes als die Gewichtungen der einzelnen Messwerte sind. |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 27. Jul 2012 13:07 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | | Anscheinend sind dann viele Fitprogramme nicht "vernünftig" da sie die Kovarianz unberücksichtigt lassen[...] |
Die Kovarianz spielt ja keine Bedeutende Rolle.
Origin kann es natürlich auch, beim Fit einfach bei Covariance 'nen Haken setzen. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 13:48 Titel: |
|
|
| Chillosaurus hat Folgendes geschrieben: | | Die Kovarianz spielt ja keine Bedeutende Rolle. |
Bei kleinen Datensätzen angeblich schon. Wollte sehen wie viel dies am kleinsten meiner Datensätze ausmacht. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 15:55 Titel: |
|
|
Also Origin installiert und damit mein Testbeispiel gerechnet. Nach meinem (möglicherweise unvollständigen) Verständnis berechnet sich der aufgrund der Regression y=a+bx für einen Wert x geschätzte Fehler ) aus der Wurzel von: aus der Wurzel von:
=\sigma^2_a + x^2\sigma^2_b + 2xu(a,b))
wobei u(a,b) die Korrelation zwischen a und b ist.
Vergleiche ich die mit Origin erhaltenen Werte mit meinen, dann ist
-> sigma a: identisch, ok.
-> sigma b: ist für den Wert x=1 identisch, ABER ich brauche den Wert für ein x leicht ausserhalb des Datenbereichs. Mit wachsendem  wächst auch der geschätzte Fehler. wächst auch der geschätzte Fehler.
-> u(a,b): Dieser Wert scheint normiert zu sein, da in den Diagonalen u(a,a) und u(b,b) die Werte 1 haben. Bedeutet dies, dass in obiger Gleichung wegen der Normierung der dritte Summand ) lauten müsste? lauten müsste? |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 27. Jul 2012 16:02 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | [...]. Nach meinem (möglicherweise unvollständigen) Verständnis berechnet sich der aufgrund der Regression y=a+bx für einen Wert x geschätzte Fehler aus der Wurzel von:
[...] |
x ist doch dein Messwert, d.h. die Messunsicherheit zu x ist allein durch deine Messapperatur und Ablesegenauigkeit etc. bestimmt. |
|
|
Jannick
Anmeldungsdatum: 25.07.2012
Beiträge: 107
|
| Jannick Verfasst am: 27. Jul 2012 16:50 Titel: |
|
|
Ich verstehe ehrlichgesagt insgesamt nicht so recht was du vor hast. Die Korrelation zweier Groessen braucht man, wenn man den Fehler eines Wertes, der mit beiden gebildet wird berechnen moechte. Sagen wir mal in deinem Fall moechtest du

berechen. Der Fehler von R ist nun nicht nur von den einzelnen Fehler  , sodern auch von deren Korrelation. Der Fehler , sodern auch von deren Korrelation. Der Fehler  berechnet sich nun folgendermassen berechnet sich nun folgendermassen
^2+(R\cdot \frac{\delta b}{b})^2 - 2\cdot\frac{a}{b^3}\cdot \text{cov}(a,b) }
<br />
)
Hiebei sieht man gut, dass der Fehler kleiner wird, wenn beide positiv korreliert sind. Dies ist klar, da das ja bedeutet, dass, wenn a groesser wird b tendentiell auch groesser wird und da man ja den Qutienten bildet sich dies ausgleicht fuer R |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 16:52 Titel: |
|
|
Dies hat in diesem Zusammenhang nichts mit dem Messfehler von x zu tun. Bezog sich dies seinerzeit auf das Thema "Fehlerellipse"?
Die beste Schätzung bzw. der kleinste Fehler bezieht sich auf das Zentrum der Daten. Wenn die Daten so transformiert werden, dass <x> und <y> der neue Koordinatenmittelpunkt sind, ist dort auch der geschätzte Fehler für y aufgrund des Fehlers für die Steigung gleich Null. Je weiter sich aber x vom Zentrum entfernt liefert der Fehler für die Steigung einen grösseren Beitrag an den Fehler für y. |
|
|
Jannick
Anmeldungsdatum: 25.07.2012
Beiträge: 107
|
| Jannick Verfasst am: 27. Jul 2012 17:04 Titel: |
|
|
Die Fehlerellipse ist eine Aequipotentialflaeche bzgl. des 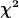 Wertes und der Fitergebnisse als Koordination. Die Ellipse ist definiert durch Wertes und der Fitergebnisse als Koordination. Die Ellipse ist definiert durch
&=&\chi_{min}^2+\Delta \chi^2
<br />
)
D.h. die wahren Werte liegen mit einer gewissen Wahrscheinlichkeit in dieser Ellipse. Wenn ihre Hauptachsen mit den Koordinatenachsen zusammenfallen liegt keine Korrelation vor. Wenn sie hingegen verdreht sind liegt Korrelation vor. Dies ist auch leicht zu verstehen. Im unkorrelierten Fall hat ein hoeheres b keine Auswirkung auf die Lage von a. Bei Korrelation hingegen impliziert bei 45 Grad Drehung hoeheres b auch hoeheres a[/latex] |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 27. Jul 2012 17:52 Titel: |
|
|
| Jannick hat Folgendes geschrieben: | | Ich verstehe ehrlichgesagt insgesamt nicht so recht was du vor hast. |
Sorry siehe diesen Beitrag erst jetzt, da inzwischen die Seite gewechselt wurde. Gemäss dieser Web-Seite http://en.wikipedia.org/wiki/Propagation_of_uncertainty müsste die Fehlerschätzung für eine lineare Regression (wenn richtig verstanden) die schon erwähnte Form haben, vielleicht besser aber so geschrieben:
_x=\sigma^2_a + x^2\sigma^2_b + 2xu(a,b))
Auf einer anderen Webseite, die ich leider nicht mehr finde, hatte ich gelesen, dass bei kleinen Datensätzen der dritte Term nicht zu vernachlässigen sei. Ich wollte jetzt bei einem meiner kleinen Datnsätze schauen wie stark sich der dritte Term tatsächlich auswirkt. Bei diesem Datensatz ist der Fehler für ein leicht extrapoliertes x zu berechnen. Der zweite Term in obiger Formel ist deshalb "bemerkbar" und sicher nicht mit dem Wert x=1 zu rechnen. Wie stark macht sich der dritte Term "bemerkbar"? Dies hängt sicher auch mit dem R^2 zusammen. Da dies im betreffenden Datensatz leider nicht so gut ist, vermute ich, dass auch der dritte Term einen "bemerkenswerten" Beitrag liefern könnte. Mein Problem ist, dass ich bisher noch nicht herausgekriegt habe wie dieser dritte Term zu berechnen ist. |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 28. Jul 2012 09:43 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | [...]Gemäss dieser Web-Seite http://en.wikipedia.org/wiki/Propagation_of_uncertainty müsste die Fehlerschätzung für eine lineare Regression (wenn richtig verstanden) die schon erwähnte Form haben, vielleicht besser aber so geschrieben:
[...] |
Nee, ich denke da hast du etwas falsch verstanden. Auf der Website ist überhaupt nicht von linearer Regression die Rede.
Die Güte des Fits wird durch Angabe deines X²-Wertes bezeichnet.
| Zitat: | | Bei diesem Datensatz ist der Fehler für ein leicht extrapoliertes x zu berechnen. Der zweite Term in obiger Formel ist deshalb "bemerkbar" |
Dann hast du deine Geradenformel
f(x)=ax+b
-->x=f(x)/a-b/a
und setzt gemäß Fehlerfortpflanzungsgesetz an:
² +( \frac{\partial x}{\partial b} \sigma_{b})² + ( \frac{\partial x}{\partial a} \frac{\partial x}{\partial b} <\sigma_{b} \sigma_{a}> )²+ \dots})_{x})
Es bietet sich natürlich auch an - und ist meistens genügend-, einfach Worst-Cases auszurechnen.
Zuletzt bearbeitet von Chillosaurus am 28. Jul 2012 12:09, insgesamt einmal bearbeitet |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 28. Jul 2012 11:11 Titel: |
|
|
| Chillosaurus hat Folgendes geschrieben: | | Nee, ich denke da hast du etwas falsch verstanden. Auf der Website ist überhaupt nicht von linearer Regression die Rede. |
Das wurde anscheinend falsch verstanden. Mein Text sagte FÜR die lineare Regression also für die Funktion f(x): y=a+bx.
Unabhängig davon, dass wir in unseren Schreibweisen a und b vertauschen: Weshalb jetzt auf einmal mit | Zitat: | f(x)=ax+b
-->x=f(x)/a-b/a |
den Fehler von x? Das Beispiel im unteren Teil der erwähnten Web-Seite zeigt nur wie die Fehlerfortpflanzung für eine Funktion f(x,y,z) zu rechnen ist, die für die Regression entsprechend auf f(a,b) anzuwenden ist. Bei der linearen Regression ist die Fehlerfortpflanzung doch von y=f(x)=a+bx zu berechnen und nicht von x. Also
und damit ergeben sich mindestens einmal die ersten beiden der drei vorher angegebenen Terme für _x) . Die Abhängigkeit des geschätzten Fehlers für y von x ist mir schon klar. Je weiter ich über die vorhandenen Daten extrapoliere desto ungenauer wird die Schätzung, d.h. der geschätzte Fehler für y vergrössert sich je weiter ein x vom Zentrum der vorhandenen Daten entfernt ist. . Die Abhängigkeit des geschätzten Fehlers für y von x ist mir schon klar. Je weiter ich über die vorhandenen Daten extrapoliere desto ungenauer wird die Schätzung, d.h. der geschätzte Fehler für y vergrössert sich je weiter ein x vom Zentrum der vorhandenen Daten entfernt ist.
P.S: Hatte versehentlich den Link zur englischsprachigen Web-Seite angegeben. "Glücklicherweise" stimmt sie bezogen auf die Ergebnisse mit der deutschsprachigen überein ( http://de.wikipedia.org/wiki/Fehlerfortpflanzung ). |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 28. Jul 2012 11:39 Titel: |
|
|
| Asterix hat Folgendes geschrieben: | [...]Bei der linearen Regression ist die Fehlerfortpflanzung doch von y=f(x)=a+bx zu berechnen und nicht von x. [...]
|
Du hast nach dem Fehler für ein extrapoliertes "x" gefragt. Dein f funktioniert natürlich völlig analog.
| Zitat: | | P.S: Hatte versehentlich den Link zur englischsprachigen Web-Seite [..]. |
I.d.R. ist die englische Version besser, da mehr Leute die verstehen und kontrollieren können. |
|
|
Asterix
Anmeldungsdatum: 30.06.2008
Beiträge: 37
|
| Asterix Verfasst am: 28. Jul 2012 12:38 Titel: |
|
|
| Chillosaurus hat Folgendes geschrieben: | | Du hast nach dem Fehler für ein extrapoliertes "x" gefragt. |
Das ist ein Misverständnis. Ich suche den Fehler von y an einer Stelle von x, einschliesslich dem Korrelationsterm. Mein Problem ist nach wie vor wie der Korrelationsterm (für y an der Stelle x) berechnet wird. |
|
|
Chillosaurus
Anmeldungsdatum: 07.08.2010
Beiträge: 2440
|
| Chillosaurus Verfasst am: 28. Jul 2012 13:01 Titel: |
|
|
Wo hakt es denn?
1. entwickle f in eine Taylorreihe um deine Bestwerte
2. ziehe f(a,b) ab
3. addiere alle linearen Terme (+ den 1. Mischterm) quadratisch auf
4. beachte die Mittelung im Mischterm, wenn die Fehler von a, b unkorreliert sind, verschwindet diese
5. Wurzel ziehen.
(s.o., du musst im Prinzip nur x durch f ersetzen) |
|
|
|

