| Autor |
Nachricht |
TomS
Moderator

Anmeldungsdatum: 20.03.2009
Beiträge: 21469
|
 TomS Verfasst am: 19. Jul 2018 17:21 Titel: Datenanalyse - Verwandtschaft von Proben TomS Verfasst am: 19. Jul 2018 17:21 Titel: Datenanalyse - Verwandtschaft von Proben |
 |
|
Wie immer - keine Antwort im Matheboard.
Gegeben sind n = 1..N Proben (hier: Single Malt Whiskies) sowie je Probe jeweils f = 1..F Geschmackskategorien X (hier: Smoke, Honey, ...) mit jeweils einem Zahlenwert. Z.B. wird einem bestimmten Whisky der Geschmack Smoke = 4, Honey = 1 etc. zugeordnet. Die zugrundeliegenden Geschmackskategorien und deren Zahlenwerte sind natürlich ziemlich subjektiv.
Ziel ist es, Ähnlichkeiten oder soetwas wie das Verwandtschaftsverhältnis zweier Whiskies m,n anzugeben. Dazu kann man zunächst die euklidische Distanz zugrundelegen:
 = \sum_{f=1}^F [X_f(m) - X_f(n)]^2)
Nun gibt es Geschmackskategorien, die den Charakter sehr deutlich dominieren. Dies kann entweder durch sehr hohe Werte auf der Skala angegeben werden, oder - bei über alle Geschmackskategorien identisch normierten Skalen - durch einen Gewichtsfaktor:
 = \sum_{f=1}^F \omega_f \, [X_f(m) - X_f(n)]^2)
Nun sind die Geschmackskategorien nicht unabhängig. Man findet Paare f,g, für die über alle getesteten Whiskies praktisch keine Korrelation vorliegt; man findet auch Paare, für die eine sehr starke Korrelation vorliegt; und es gibt Paare, für die eine Antikorrelation vorliegt. Z.B. gehen Rauch und Torf oft Hand-in-Hand, und es liegt eine Korrelation nahe Eins vor, während sich Rauch und Süße eher ausschließen, d.h. es liegt eine Korrelation nahe minus Eins vor (konkret: bei Rauch = 4 liegt Süße bei 0, manchmal 1 u.u.). Rauch und Torf bedeuten im Sinne des Verwandhaftsgrades zweier Whiskies wohl eher das selbe und sollten nicht unabhängig bewertet werden. Generell könnte man bei sehr starker Korrelation oder Antikorrelation zweier Merkmale f,g sowie Null Korrelation mit weiteren Merkmalen h, ... auf ein Merkmal f oder g verzichten. In der Praxis findet man für die Paare eher beliebige Zwischenwerte im Intervall [-1,+1].
Offensichtlich sollten unterschiedliche Paare von Geschmackskategorien unterschiedlich behandelt werden, d.h. man gelangt zu
 = \sum_{\langle f,g \rangle} \omega_{fg} \, [X_f(m) - X_g(n)]^2)
Dabei wird über Paare <f,g> genau einmal summiert.
Frage: Wie kann man dieser Tatsache Rechnung tragen? Was wäre eine sinnvolle und allgemeingültige Methode, die Gewichte omega ausgehend von den Werten X und deren Korrelationen über alle Proben o.ä. festzulegen? Insbs. wenn beliebige Korrelationen vorliegen, d.h. nicht nur die Extremfälle 1, 0, -1?
Alternative: Man könnte stattdessen eine geeignete (lineare) Transformation von X ansetzen, so dass die Summe in f,g wieder diagonal wird. Auch dabei weiß ich nicht, welche Transformation anzusetzen wäre bzw. wie man diese aus den Daten ableiten könnte.
Frage: Kennt jemand eine derartige Analysemethode bzw. einen Abstandsbegriff für nicht-unabhängige Merkmale?
_________________
Niels Bohr brainwashed a whole generation of theorists into thinking that the job (interpreting quantum theory) was done 50 years ago. |
|
 |
ML
Anmeldungsdatum: 17.04.2013
Beiträge: 3563
|
|
|
TomS
Moderator
Anmeldungsdatum: 20.03.2009
Beiträge: 21469
|
| TomS Verfasst am: 21. Jul 2018 15:04 Titel: |
|
|
Super, danke.
Wenn ich das richtig verstehe, dann gilt für Erwartungswert und Kovararianzmatrix
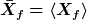
 \, (X_g - \bar{X}_g) \rangle)
Für zwei Proben m, n folgt dann gemäß der Mahalanobis-Distanz
 = \sum_{f,g} [X_f(m) - X_f(n)] \, (S^{-1})_{fg} \, [X_g(m) - X_g(n)] )
Danke nochmal, das hilft mit sehr.
_________________
Niels Bohr brainwashed a whole generation of theorists into thinking that the job (interpreting quantum theory) was done 50 years ago. |
|
|
index_razor
Anmeldungsdatum: 14.08.2014
Beiträge: 3259
|
| index_razor Verfasst am: 21. Jul 2018 15:33 Titel: Re: Datenanalyse - Verwandtschaft von Proben |
|
|
| TomS hat Folgendes geschrieben: |
Ziel ist es, Ähnlichkeiten oder soetwas wie das Verwandtschaftsverhältnis zweier Whiskies m,n anzugeben.
|
Das ist, denke ich, keine Frage, die sich mit Hilfe der Methoden zur Datenanalyse beantworten läßt. Diese können dir zwar sagen, welche Informationen in deinen Daten vorhanden ist, aber nicht, welche davon du "sinnvollerweise" verwenden mußt. Die relevanten Größen und ihren Zusammenhang mit deinen Daten mußt du schon kennen, bevor du anfängst zu analysieren. Und sie hängen natürlich von der Frage ab, die du beantworten willst. Kannst du hierzu etwas mehr Hintergrund liefern?
Willst du vielleicht wissen wie wahrscheinlich jemandem mit Vorliebe für Sorte X auch Sorte Y zusagt, um z.B. Empfehlungen auszusprechen? Oder willst du Rückschlüsse auf Reifungsmethode, Reifungszeit, Destillationsverfahren etc. ziehen? (Da ich keine Ahnung von Whisky habe, Rede ich hier vermutlich Unsinn, aber du verstehst worauf ich hinaus will.) Zu jeder dieser Fragestellungen gehört sicher ein bestimmter sinnvoller Begriff von "Verwandschaft", der nicht unbedingt in allen Fällen derselbe ist.
Nimm ein anderes Beispiel: sicher lassen sich aus bestimmten Merkmalen wie Augenfarbe, Haarfarbe, Körpergröße etc. Rückschlüsse auf das Verwandtschaftsverhältnis zweier Personen ziehen. Aber der Grad ihrer Verwandtschaft ist keine Funktion auf dem Raum dieser Merkmale, sondern hat eher damit zu tun, vor wie vielen Generationen ihr letzter gemeinsamer Vorfahre gelebt hat, wie viele gemeinsame Gene sie besitzen oder ähnliche Metriken. Daß dies sinnvolle Begriffe von "Verwandtschaftsgrad von Personen" sind, können dir Stichproben von Körpermaßen natürlich nicht sagen. Ihre Analyse verrät dir nur, welche Schlüsse über den Verwandtschaftsgrad gerechtfertigt sind.
Wie kommst du also darauf, daß "Verwandschaft" von Whiskysorten etwas mit "Smoke", "Honey" und "Torf" zu tun hat? Warum nicht Farbe, Schmelzpunkt und Gehalt an Fuselölen? |
|
|
TomS
Moderator
Anmeldungsdatum: 20.03.2009
Beiträge: 21469
|
| TomS Verfasst am: 22. Jul 2018 01:53 Titel: |
|
|
Evtl. war das verwirrend formuliert, Verwandtschaft meint einfach eine verwandte Geschmacksrichtung.
_________________
Niels Bohr brainwashed a whole generation of theorists into thinking that the job (interpreting quantum theory) was done 50 years ago. |
|
|
index_razor
Anmeldungsdatum: 14.08.2014
Beiträge: 3259
|
| index_razor Verfasst am: 23. Jul 2018 13:21 Titel: |
|
|
| TomS hat Folgendes geschrieben: | | Evtl. war das verwirrend formuliert, Verwandtschaft meint einfach eine verwandte Geschmacksrichtung. |
Vielleicht formuliere ich auch mal anders, was ich meine: In der Überschrift steht das Stichwort "Datenanalyse". Diese betreibt man normalerweise auf der Suche nach "Evidenz", bzw. einer Art "Signal", innerhalb einer Menge von Daten. Du hast zwar angegeben welche Art von Daten vorliegen. Aber die eigentliche Frage, die im vorliegenden Fall noch vollkommen ungeklärt ist, lautet "Evidenz wofür?"
Du kannst natürlich alle möglichen Metriken auf deinen Daten definieren, aber ohne zu wissen, wonach du eigentlich suchst, ist, denke ich, keine davon besser als irgendeine andere. Wenn erst noch geklärt werden muß, was eine sinnvolle Quantifizierung des Begriffs "Geschmacksverwandtschaft" ist und wozu er gut sein soll, dann benötigst du vorerst wohl weder Daten noch Analysemethoden. Du benötigst eher ein Modell, in dem diese "Verwandtschaft" sowohl irgendeinen Bezug zu beobachtbaren Größen, als auch zu solchen Größen hat, die du aus der Beobachtung inferieren willst. Ohne einen solchen Zusammenhang ist m.E. jede quantitative Definition von "Verwandschaft" beliebig und belanglos. Nimm an, du errechnest eine Mahalanobis-Distanz von  = 42.314) . Was fängst du nun mit diesem Wert an? . Was fängst du nun mit diesem Wert an?
Die Art der Frage scheint mir deshalb weniger auf ein Problem der Datenanalyse hinauszulaufen, als vielmehr auf eines der Modellbildung. |
|
|
TomS
Moderator
Anmeldungsdatum: 20.03.2009
Beiträge: 21469
|
| TomS Verfasst am: 23. Jul 2018 14:36 Titel: |
|
|
Es geht um beides.
Was ich benötige ist ein mathematischer Rahmen, innerhalb dessen derartige Modelle entwickelt werden können. Das kann eine sehr spezielle Metrik oder auf ein allgemeinerer Rahmen sein.
Das größte Problem ist das subjektive Geschmacksempfinden. Insbs. sind bestimmte Geschmackskategorien dominierender als andere, d.h. im Rahmen der Modellbildung müssen auch derartige subjektive Aspekte diskutiert werden.
Letztlich muss man ein gewähltes Modell anhand des eigenen subjektiven Geschmacksempfindens testen: wenn mir das Modell sagt, A und B seien eng, A und C eher weitläufigen verwandt, ich das jedoch anders empfinde, dann muss ich das Modell anpassen. Ob das auf eine andere Wahl von Parametern zur Gewichtung der Geschmackskategorien rausläuft, auf die Wahl einer anderen Abstandsfunktion oder gar eines völlig anderen Ansatzes ist eine andere Frage.
Die Frage nach dem Signal ist subjektiv recht einfach: zwei Whiskies schmecken ähnlich oder zwei Whiskies schmecken völlig unterschiedlich. Ich suche ein mathematisches Modell, das meinem Geschmacksempfinden in ausgewählten Fällen - insbs. Extremfällen - nahe kommt.
_________________
Niels Bohr brainwashed a whole generation of theorists into thinking that the job (interpreting quantum theory) was done 50 years ago. |
|
|
|
|

